prometheus 监测 kubernetes 控制平面
Overview
对于 kubernetes 集群的控制平面组件,监控是必要的, 他可以帮助我们获取到集群的整体负载压力,并在核心组件出问题的时候配合告警让管理员及时发现问题,及时处理,更稳定的保证集群的生命周期。
一、Prometheus 如何自动发现 Kubernetes Metrics 接口?
prometheus 收集 kubernetes 集群中的指标有两种方式,一种是使用 crd(servicemonitors.monitoring.coreos.com)的方式,主要通过标签匹配;另一种是通过 scrape_config,支持根据配置好的"relabel_configs"中的具体目标, 进行不断拉取(拉取间隔为"scrape_interval")
- 配置权限:
k8s 中 RBAC 支持授权资源对象的权限,比如可以 get、list、watch 集群中的 pod,还支持直接赋予对象访问 api 路径的权限,比如获取/healthz, /api 等, 官方对于 non_resource_urls 的解释如下:
non_resource_urls - (Optional) NonResourceURLs is a set of partial urls that a user should have access to. *s are allowed, but only as the full, final step in the path Since non-resource URLs are not namespaced, this field is only applicable for ClusterRoles referenced from a ClusterRoleBinding. Rules can either apply to API resources (such as "pods" or "secrets") or non-resource URL paths (such as "/api"), but not both.
既然 prometheus 要主动抓取指标,就必须对他使用的 serviceaccount 提前进行 RBAC 授权:
1# clusterrole.yaml
2apiVersion: rbac.authorization.k8s.io/v1
3kind: ClusterRole
4metadata:
5 name: monitor
6rules:
7- apiGroups: [""]
8 resources:
9 - nodes
10 - pods
11 - endpoints
12 - services
13 verbs: ["get", "list", "watch"]
14- nonResourceURLs: ["/metrics"]
15 verbs: ["get"]
16
17# clusterrolebinding
18apiVersion: rbac.authorization.k8s.io/v1
19kind: ClusterRoleBinding
20metadata:
21 name: prometheus-api-monitor
22roleRef:
23 apiGroup: rbac.authorization.k8s.io
24 kind: ClusterRole
25 name: monitor
26subjects:
27- kind: ServiceAccount
28 name: prometheus-operator-nx-prometheus
29 namespace: monitor
- 获取 apiserver 自身的 metric 信息:
prometheus 中配置"scrape_config", 或者 prometheus-operator 中配置"additionalScrapeConfigs", 配置获取 default 命名空间下的 kubernetes endpoints
1- job_name: 'kubernetes-apiservers'
2 kubernetes_sd_configs:
3 - role: endpoints
4 scheme: https
5 tls_config:
6 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
7 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
8 relabel_configs:
9 - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
10 action: keep
11 regex: default;kubernetes;https
- 获取 controller-manager、scheduler 的 metric 信息:
controller-manager 和 scheduler 因为自身暴露 metric 接口,需要修改对应 manifests 下的静态 pod 文件,添加匹配的 annotations 即可完成抓取:
1# prometheus端配置
2kubernetes_sd_configs:
3 - role: pod
4 relabel_configs:
5 - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
6 action: "keep"
7 regex: "true"
8 - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
9 action: replace
10 regex: ([^:]+)(?::\d+)?;(\d+)
11 replacement: $1:$2
12 target_label: __address__
13 - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
14 action: replace
15 target_label: __metrics_path__
16 regex: "(.+)"
17 - action: labelmap
18 regex: __meta_kubernetes_pod_label_(.+)
19 - source_labels: [__meta_kubernetes_namespace]
20 action: replace
21 target_label: kubernetes_namespace
22 - source_labels: [__meta_kubernetes_pod_name]
23 action: replace
24 target_label: kubernetes_pod_name
25
26# controller-manager配置:
27metadata:
28 annotations:
29 prometheus_io_scrape: "true"
30 prometheus.io/port: "10252"
31
32# scheduler配置:
33metadata:
34 annotations:
35 prometheus_io_scrape: "true"
36 prometheus.io/port: "10251"
- 获取 etcd 的 metric 信息:
etcd 是跑在物理机上的,所以我们先创建对应的 endpoints 绑定好 service,然后采用 servicemonitor 的方式去匹配获取 etcd 的监控指标:
1# service.yaml
2apiVersion: v1
3kind: Service
4metadata:
5 name: etcd-k8s
6 namespace: kube-system
7 labels:
8 k8s-app: etcd
9spec:
10 type: ClusterIP
11 clusterIP: None
12 ports:
13 - name: port
14 port: 2379
15 protocol: TCP
16
17# endpoint.yaml
18apiVersion: v1
19kind: Endpoints
20metadata:
21 name: etcd-k8s
22 namespace: kube-system
23 labels:
24 k8s-app: etcd
25subsets:
26- addresses:
27 - ip: xx.xx.xx.xx
28 - ip: xx.xx.xx.xx
29 - ip: xx.xx.xx.xx
30 ports:
31 - name: port
32 port: 2379
33 protocol: TCP
34
35# servicemonitor.yaml(需要配置好相关的证书)
36apiVersion: monitoring.coreos.com/v1
37kind: ServiceMonitor
38metadata:
39 name: etcd-k8s
40 namespace: monitor
41 labels:
42 k8s-app: etcd-k8s
43 release: prometheus-operator-nx
44spec:
45 jobLabel: k8s-app
46 endpoints:
47 - port: port
48 interval: 30s
49 scheme: https
50 tlsConfig:
51 caFile: /ca.pem
52 certFile: /server.pem
53 keyFile: /server-key.pem
54 insecureSkipVerify: true
55 selector:
56 matchLabels:
57 k8s-app: etcd
58 namespaceSelector:
59 matchNames:
60 - kube-system
61
62# 最后附上etcd secret的创建方法,将etcd证书挂载进入提供连接使用
63apiVersion: v1
64data:
65 ca.pem: xx
66 server.pem: xx
67 server-key.pem: xx
68kind: Secret
69metadata:
70 name: etcd-certs
71 namespace: monitor
72type: Opaque
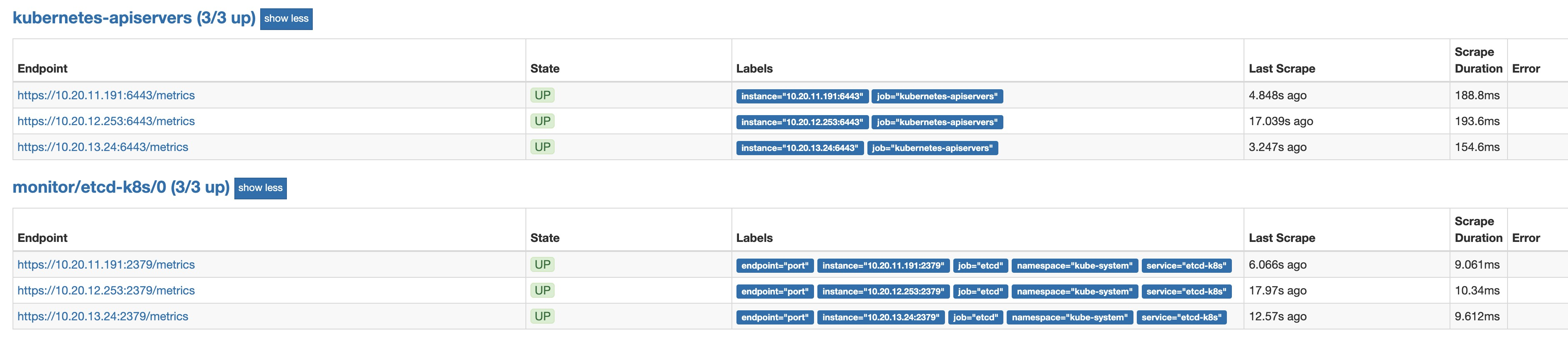
二、我该重点关注哪些 control plane 指标?
- apiserver: 其中计算延迟可以采用"percentiles"而不是平均数去更好的展示延迟出现情况
apiserver_request_duration_seconds: 计算读(Non-LIST)请求,读(LIST)请求,写请求的平均处理时间
apiserver_request_total: 计算 apiserver 的 QPS、计算读请求、写请求的成功率; 还可以计算请求错误数量以及错误码
apiserver_current_inflight_requests: 计算正在处理的读、写请求
apiserver_dropped_requests_total: 计算失败的请求
- controller-manager:
leader_election_master_status: 关注是否有 leader
xxx_depth: 关注正在调和的控制队列深度
- scheduler:
leader_election_master_status: 关注是否有 leader
scheduler_schedule_attempts_total: 帮助查看是否调度器不能正常工作; Number of attempts to schedule pods, by the result. 'unschedulable' means a pod could not be scheduled, while 'error' means an internal scheduler problem
scheduler_e2e_scheduling_duration_seconds_sum: scheduler 调度延迟(参数弃用)
rest_client_requests_total: client 请求次数(次重要); Number of HTTP requests, partitioned by status code, method, and host
- etcd:
etcd_server_has_leader: etcd 是否有 leader
etcd_server_leader_changes_seen_total: etcd leader 切换的次数,如果太频繁可能是一些连接不稳定现象或者 etcd 集群负载过大
etcd_server_proposals_failed_total: 一个提议请求是需要完整走过 raft protocol 的,这个指标帮助我们提供请求出错次数,大多数情况是 etcd 选举 leader 失败或者集群缺乏选举的候选人
etcd_disk_wal_fsync_duration_seconds_sum/etcd_disk_backend_commit_duration_seconds_sum: etcd 磁盘存储了 kubernetes 的所有重要信息,如果磁盘同步有很大延迟会影响 kubernetes 集群的操作, 此指标提供了 etcd 磁盘同步的平均延迟
etcd_debugging_mvcc_db_total_size_in_bytes: etcd 各节点容量
etcd_network_peer_sent_bytes_total/etcd_network_peer_received_bytes_total: 可以计算 etcd 节点的发送/接收数据速率
grpc_server_started_total: 可以用于计算 etcd 各个方法的调用速率
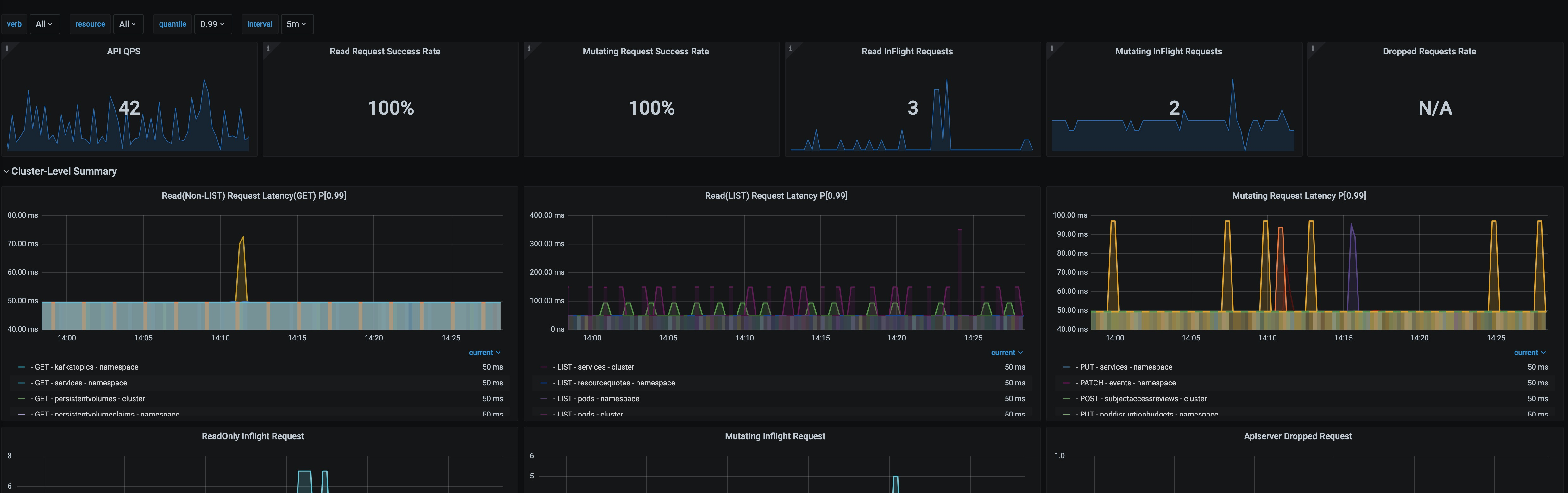
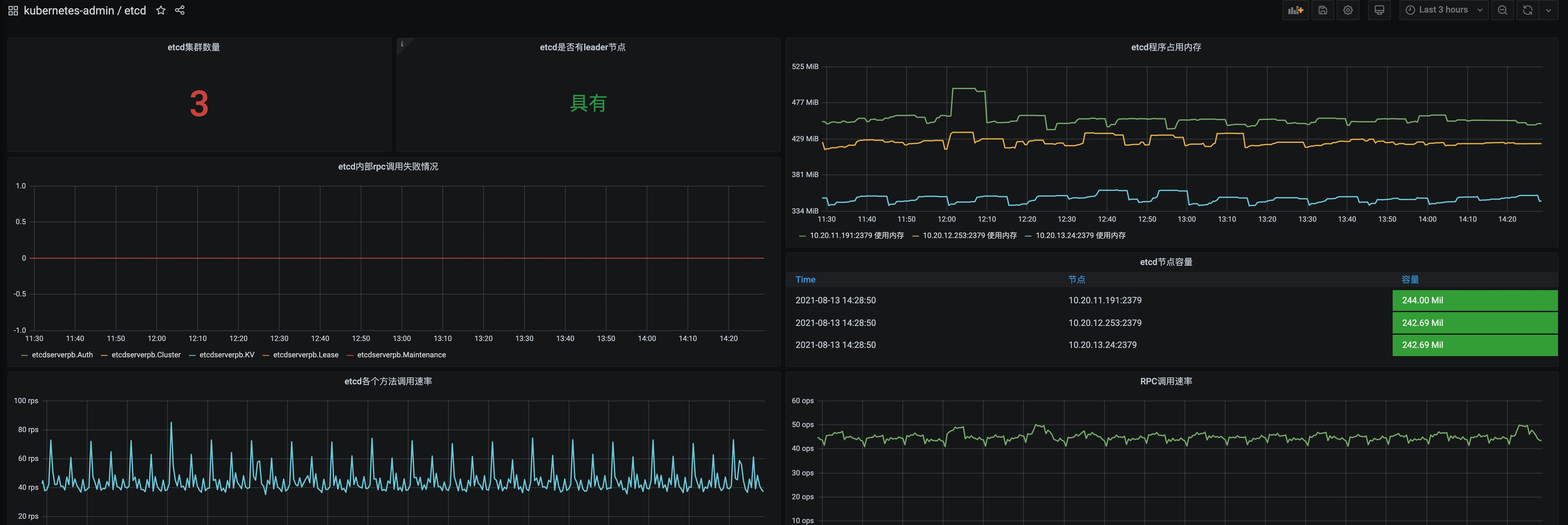
最后采用的 kubernetes 维护界面由:apiserver 专用仪表盘、etcd 仪表盘、综合控制平面仪表盘和证书监控组成;并且在维护使用过程中根据不同参数,不断调整, 够用就行。
参考链接:
https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/cluster_role
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
https://www.datadoghq.com/blog/kubernetes-control-plane-monitoring/
https://sysdig.com/blog/monitor-kubernetes-api-server/
https://sysdig.com/blog/monitor-etcd/